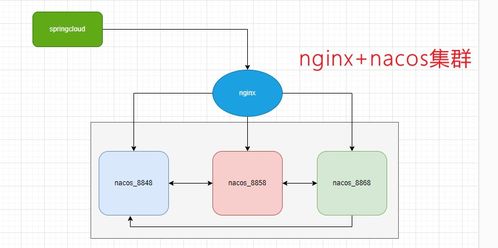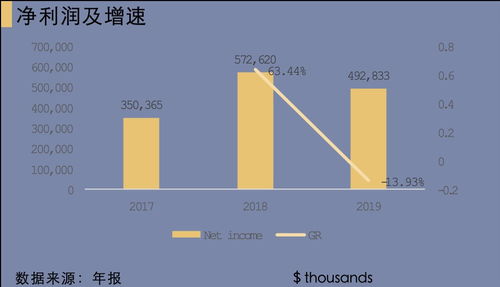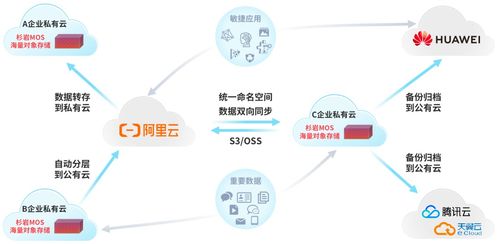
在當今大數據時代,數據倉庫(數倉)已成為企業數據管理和分析的核心基礎設施。一個設計良好的數據倉庫通常采用分層架構,每一層都承擔著特定的數據處理和存儲功能,共同構建起高效、可靠的數據支持服務。本文將詳細解析數倉分層的設計理念,以及各層在數據處理和存儲支持服務中的關鍵角色。
一、數據倉庫分層架構概述
數據倉庫分層是一種將數據處理流程模塊化和標準化的設計方法,通常包括數據接入層(ODS)、數據明細層(DWD)、數據匯總層(DWS)和數據應用層(ADS)。這種分層設計有助于提高數據處理的效率、保證數據質量,并支持靈活的數據應用。
二、各層的數據處理與存儲支持服務
1. 數據接入層(ODS,Operational Data Store)
ODS層是數據倉庫的第一站,直接對接業務系統的數據源。其主要職責是:
- 數據采集:通過ETL(抽取、轉換、加載)或實時流處理技術,從業務數據庫、日志文件、API等源頭獲取原始數據。
- 數據存儲:以近原貌的形式存儲數據,通常保留短期歷史(如7-30天),支持增量或全量同步。
- 服務支持:為數據清洗和整合提供基礎,減少對業務系統的直接查詢壓力。
2. 數據明細層(DWD,Data Warehouse Detail)
DWD層是數據清洗和標準化的核心,目標是為上層提供高質量、一致的明細數據。其關鍵服務包括:
- 數據清洗:去除重復、錯誤或無效數據,統一格式和編碼(如日期、貨幣單位)。
- 數據整合:關聯多源數據,生成具有業務意義的寬表,例如將訂單、用戶和商品信息合并。
- 維度建模:采用星型或雪花模型,區分事實表和維度表,提升查詢性能。
- 存儲優化:通常采用列式存儲(如Parquet)和分區策略,平衡存儲成本與訪問效率。
3. 數據匯總層(DWS,Data Warehouse Summary)
DWS層面向分析場景,通過預聚合減少重復計算。其數據處理與存儲服務體現為:
- 數據聚合:按時間(如日、周、月)、業務維度(如地區、產品類別)進行匯總,生成指標數據。
- 模型優化:設計主題域模型(如銷售、用戶行為),支持快速的多維度分析。
- 性能支持:存儲預計算的結果,直接服務于報表和即席查詢,降低計算延遲。
4. 數據應用層(ADS,Application Data Store)
ADS層是面向最終用戶或應用系統的接口,強調靈活性和響應速度。其服務包括:
- 數據輸出:導出指標、報表或API接口,供BI工具、推薦系統等直接使用。
- 個性化存儲:根據應用需求定制數據結構,如寬表、緩存或內存數據庫。
- 實時支持:結合流處理技術,為實時監控和決策提供低延遲數據。
三、分層架構的優勢與實施要點
分層設計不僅簡化了數據處理流程,還帶來了多重好處:
- 解耦與復用:各層職責清晰,便于團隊協作和代碼復用。
- 數據質量保障:通過逐層校驗和清洗,確保最終數據的準確性。
- 成本與效率平衡:冷熱數據分級存儲(如ODS用低成本存儲,ADS用高性能存儲),優化資源利用。
在實施中,企業需注意:
- 結合業務需求選擇分層粒度,避免過度設計。
- 采用自動化工具(如Apache Airflow、dbt)管理數據處理任務。
- 建立數據血緣和元數據管理,提升可維護性。
數據倉庫分層架構通過系統化的數據處理和存儲支持服務,為企業構建了從原始數據到智慧決策的橋梁。隨著云原生和實時計算技術的發展,分層設計也在不斷演進(如增加實時層),但其核心目標始終不變:以高效、可靠的方式釋放數據價值,驅動業務增長。